
Comment Import
github-pages jekyll Following on from my previous update regarding the migration to Github Pages I decided to look at the importing of previous comments and have completed that process.
I had previously thought about just discarding the comments but after reading through them it was clear that there was an amount of good content in there and seeing as people had taken the time to leave them I thought it was a bit harsh to just thrown them away.
That being said, I have made the decision not to look at implementing a comment system into the new blog - if someone wants to contact me there’s always Twitter and Mastodon.
Being a relative newbie to the whole Jekyll platform and the Liquid language I needed to do some research but quickly fell onto a post by Phil Haack where he discusses this very topic. Now, Phil goes a lot further than I intended to go - he’s accepting new comments and even though he doesn’t use a third party service he does acknowledge that it does leave him exposed to comment spam, something I’d be keen to avoid.
Adding the comment data
My solution (heavily based on the above post) makes use of the built-in ‘Data Files’ functionality within Jekyll so the first thing to do was to create a home for the comment data.
- I created a new
_datafolder at the root level and added acommentsfolder within that. - I then created a new folder within
commentsfor each post that contained one or more comments- These folders are named based on the slug of the url, the slug for this post is
importing-commentsas can be seen in the browser address bar.
- These folders are named based on the slug of the url, the slug for this post is
- Within each
slugfolder I added a .json file for each comment
My _data folder looks like this:
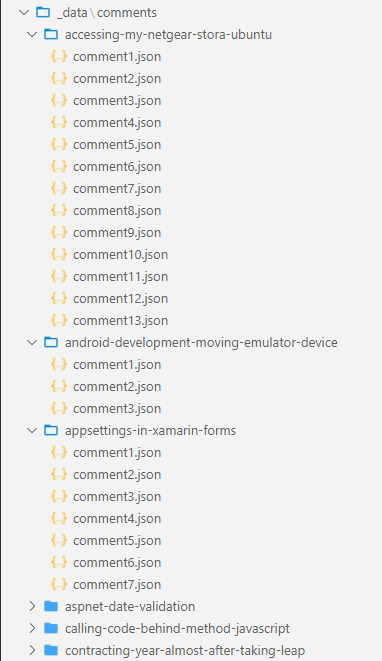
Each comment file contains data in the following format (the content being pulled from the old site which was running at the time):
{
"date": "2011-09-15T19:58:00.0000000+00:00",
"name": "Dave",
"avatar": "https://secure.gravatar.com/avatar/574ced245d2cbf3d32eb903515de1ebc?s=42&d=identicon&r=g",
"message": "Thanks for your input Allen"
}
So now I have the data - what am I going to do with it? How do I get it attached to the appropriate posts?
Processing & Displaying the Data
To process the data we need to include a Liquid script to locate the appropriate data for a given post and generate the markup for each comment as required.
Within my _includes folder I added a file called comments.html with the following content:
{% capture default_slug %}{{ page.slug | default: (page.title | slugify) }}{% endcapture %}
{% capture slug %}{{ (page.slug | fallback: default_slug) | downcase | replace: '.', '-' }}{% endcapture %}
{% assign comments_map = site.data.comments[slug] %}
{% assign comments = site.emptyArray %}
{% for comment in comments_map %}
{% assign comments = comments | push: comment[1] %}
{% endfor %}
{% assign comment_count = comments | size %}
<div id="comments">
<h2 style="margin-bottom: 0;">Comments</h2>
<span style="font-size: 0.8em;">Comments are now closed</span>
<h3 id="comment-count">{% if comment_count == 1 %}One response{% else %}{{ comment_count }} responses{% endif %}
</h3>
<ol id="comments-list" style="list-style-type: none; margin-left: 0;">
{% assign sorted_comments = comments | sort: 'date' %}
{% for comment in sorted_comments %}
<li>
{% include comment.html %}
</li>
{% endfor %}
</ol>
</div>
The Liquid script before the opening div sets a number of variables which will be used in the generated HTML. As this will be called from within a Post the page. references will relate to that Post so the slug will be specific to the Post being generated at that time.
Most of this is, I think, fair straightforward, but the one gotcha that caught me out was the site.emptyArray reference … where the hell is that coming from?
Well, most of this script was lifted from Phil Haacks blog post (see above) but I wasn’t using the entire solution he presented and I’d missed something. I needed to add a variable to the _config.yml file for the site.
emptyArray: []
I tried using the [] directly in the script but the compiler was having none of it so just add the line and move on ;-)
You’ll notice a reference to comment.html between the <li> tags in the above markup - that will hold the markup of each comment - mine looks like this (bear in mind, I’m not a designer - but it works well enough for now);
<table class="comment">
<tr>
<td rowspan="2" style="width: 50px;">
{% if comment.url %}
<a href="{{ comment.url }}" rel="nofollow">
<img alt="Avatar for {{ comment.name | xml_escape }}" style="float: left;" src="{{comment.avatar}}"
class="avatar" height="48" width="48">
</a>
{% else %}
<img alt="Avatar for {{ comment.name | xml_escape }}" style="float: left;" src="{{comment.avatar}}" class="avatar"
height="48" width="48">
{% endif %}
</td>
<td>
<span class="author" style="font-weight: bold; padding-left: 2px;">
{% if comment.url %}
<a href="{{ comment.url }}" rel="nofollow">{{ comment.name | xml_escape }}</a>
{% else %}
{{ comment.name | xml_escape }}
{% endif %}
</span>
</td>
</tr>
<tr>
<td style="padding-left: 2px;">
{{ comment.date | date: '%B' }}
{% assign d = comment.date | date: "%-d" %}
{% case d %}
{% when '1' or '21' or '31' %}{{d}}st,
{% when '2' or '22' %}{{d}}nd,
{% when '3' or '23' %}{{d}}rd,
{% else %}{{d}}th,
{% endcase %}
{{ comment.date | date: '%Y' }}
</td>
</tr>
<tr>
<td colspan="2" style="padding-left: 2px;">
{{ comment.message | markdownify }}
</td>
</tr>
</table>
Putting it all together
The final step in this process is to wire up the generate of the comments to each post - and that’s the easy part.
Within your post.html file in your _layouts folder add the following line where you want the comments to be displayed:
{% include comments.html %}
That’s it - you’re good to go.
Comments
Comments are now closedOne response
This is a test comment. I can add basic markdown for bold & italic text as well as
inline codeand links